JS异步错误处理
JavaScript允许抛出异常,用一个try/catch 语句块捕获。如果抛出的异常未被捕获,大多数 JavaScript环境都会提供一个有用的堆栈轨迹。举个例子,下面这段代码由于 ‘{‘为无效 JSON对象而抛出异常。
1 | function JSONToObject(jsonStr) { |
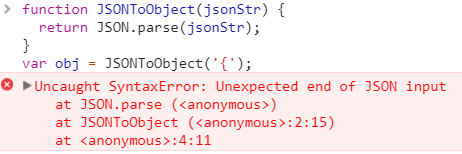
堆栈轨迹不仅告诉我们哪里抛出了错误,而且说明了最初出错的地方:第4行代码。遗憾的是,自顶向下地跟踪异步错误起源并不都这么直截了当。
回调内抛出的错误
如果从异步回调中抛出错误,会发生什么事?让我们先来做个测试。1
2
3
4
5
6
7setTimeout(function A() {
setTimeout(function B() {
setTimeout(function C() {
throw new Error('Something terrible has happened!');
}, 0);
}, 0);
}, 0);
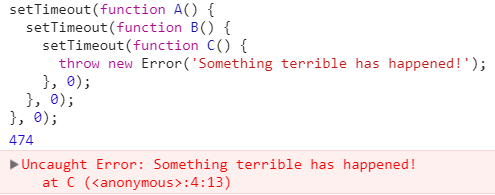
上述应用的结果是一条极其简短的堆栈轨迹。A和 B发生了什么事?为什么它们没有出现在堆栈轨迹中?这是因为运行 C 的时候,A和 B并不在内存堆栈里。这 3个函数都是从事件队列直接运行的。
基于同样的理由,利用 try/catch 语句块并不能捕获从异步回调中抛出的错误。下面进行演示。1
2
3
4
5
6
7try {
setTimeout(function() {
throw new Error('Catch me if you can!');
}, 0);
} catch (e) {
console.error(e);
}
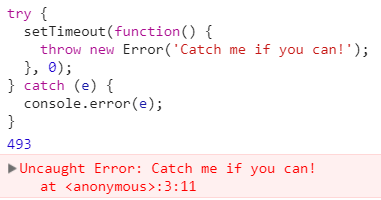
这里的 try/catch 语句块只捕获 setTimeout函数自身内部发生的那些错误。因为 setTimeout 异步地运行其回调,所以即使延时设置为 0,回调抛出的错误也会直接流向应用程序的未捕获异常处理器。
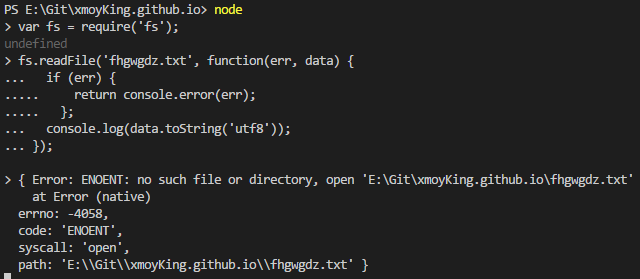
总的来说,取用异步回调的函数即使包装上 try/catch 语句块,也只是无用之举。(特例是,该异步函数确实是在同步地做某些事且容易出错。例如,Node的 fs.watch(file,callback) 就是这样一个函数,它在目标文件不存在时会抛出一个错误。)正因为此,Node.js中的回调几乎总是接受一个错误作为其首个参数,这样就允许回调自己来决定如何处理这个错误。举个例子,下面这个 Node 应用尝试异步地读取一个文件,还负责记录下任何错误(如“文件不存在”)。
1 | var fs = require('fs'); |
客户端 JavaScript 库的一致性要稍微差些,不过最常见的模式是,针对成败这两种情形各规定一个单独的回调。jQuery 的 Ajax 方法就遵循了这个模式。1
2
3
4$.get('/data', {
success: successHandler,
failure: failureHandler
});
不管 API 形态像什么,始终要记住的是,只能在回调内部处理源于回调的异步错误。
未捕获异常的处理
如果是从回调中抛出异常的,则由那个调用了回调的人负责捕获该异常。但如果异常从未被捕获,又会怎么样?这时,不同的 JavaScript环境有着不同的处理规则……
在浏览器环境中
现代浏览器会在开发人员控制台显示那些未捕获的异常,接着返回事件队列。要想修改这种行为,可以给 window.onerror 附加一个处理器。如果 windows.onerror 处理器返回 true ,则能阻止浏览器的默认错误处理行为。1
2
3window.onerror = function(err) {
return true; //彻底忽略所有错误
};
在生产环境下,会考虑某种 JavaScript 错误处理服务,譬如Errorception 。Errorception 提供了一个现成的windows.onerror 处理器,它向应用服务器报告所有未捕获的异常,接着应用服务器发送消息通知我们。
在 Node.js 环境中
在 Node 环境中, window.onerror 的类似物就是 process 对象的uncaughtException 事件。正常情况下,Node应用会因未捕获的异常而立即退出。但只要至少还有一个 uncaughtException 事件处理器,Node应用就会直接返回事件队列。1
2
3process.on('uncaughtException', function(err) {
console.error(err); //避免了关停的命运!
});
但是,自 Node 0.8.4 起, uncaughtException 事件就被废弃了。据其文档所言,
对异常处理而言, uncaughtException 是一种非常粗暴的机制, 它在将来可能会被放弃……
请勿使用 uncaughtException ,而应使用 Domain 对象。
Domain 对象又是什么?你可能会这样问。Domain 对象是事件化对象,它将 throw 转化为 ‘error’ 事件。下面是一个例子。1
2
3
4
5
6
7
8
9
10
11var myDomain = require('domain').create();
myDomain.run(function() {
setTimeout(function() {
throw new Error('Listen to me!')
}, 50);
});
myDomain.on('error', function(err) {
console.log('Error ignored!');
});
源于延时事件的 throw 只是简单地触发了 Domain对象的错误处理器。Domain 对象让 throw 语句生动了很多。
抛出还是不抛出
遇到错误时,最简单的解决方法就是抛出这个错误。在 Node代码中,大家会经常看到类似这样的回调:1
2
3
4function(err) {
if (err) throw err;
// ...
}
在生产环境下,允许例行的异常及致命的错误像踢皮球一样踢给全局处理器,这是不可接受的。
如果抛出那些自己知道肯定会被捕获的异常呢?这种做法同样凶险万分。2011年,Isaac Schlueter(npm的开发者,在任的 Node开发负责人)就主张 try/catch 是一种“反模式”的方式。
try/catch 只是包装着漂亮花括弧的 goto 语句。一旦跑去处理错误,就无法回到中断之处继续向下执行。更糟糕的是,通过 throw 语句的代码,完全不知道自己会跳到什么地方。
返回错误码的时候,就相当于正在履行合约。抛出错误的时候,就好像在说,“我知道我正在和你说话,但我现在不想搭理你,我要先找你老板谈谈”,这太粗俗无礼了。如果不是什么紧急情况,请别 这么做;如果确实是紧急情况,则应该直接崩溃掉。
Schlueter 提倡完全将 throw 用作断言似的构造结构,作为一种挂起应用的方式——当应用在做完全没预料到的事时,即挂起应用。Node社区主要遵循这一建议,尽管这种情况可能会随着 Domain 对象的出现而改变。
那么,关于异步错误的处理,目前的最佳实践是什么呢?我认为应该听从 Schlueter 的建议:如果想让整个应用停止工作,请勇往直前地大胆使用 throw 。否则,请认真考虑一下应该如何处理错误。是想给用户显示一条出错消息吗?是想重试请求吗?
毫无疑问,解决JS异常问题的答案来自于 Promise 和 generator